Qu’est ce qu’un RAG ? Définition et usages en entreprise
L’intelligence artificielle générative a radicalement transformé les attentes des entreprises en matière de productivité et de gestion de l’information. Cependant, après l’enthousiasme initial suscité par des outils comme ChatGPT ou Gemini, de nombreux décideurs se sont heurtés à une limite de taille : ces modèles, bien qu’extrêmement intelligents, ne connaissent rien de ce qui se passe à l’intérieur des murs de leur organisation. Ils ignorent vos derniers contrats, vos procédures de sécurité spécifiques ou le compte-rendu de la réunion de la veille. C’est pour combler ce fossé entre l’intelligence universelle de l’IA et les données privées de l’entreprise qu’a été créée l’architecture RAG, pour Retrieval-Augmented Generation, ou Génération Augmentée par la Récupération.
Définition : Le pont entre l’IA et vos données privées
Le RAG est une architecture logicielle qui permet de coupler un grand modèle de langage (LLM), tel que GPT-4 ou Claude, à une source de données externe, dynamique et totalement privée. Contrairement aux idées reçues, le RAG n’est pas un réentraînement de l’IA. Si l’on devait utiliser une métaphore, le modèle de langage classique est comme un étudiant brillant qui a lu tous les livres du monde jusqu’à l’année dernière, mais qui n’a pas accès à vos archives personnelles. Le RAG consiste à donner à cet étudiant un accès en temps réel à votre bibliothèque privée et à lui demander de ne répondre qu’en s’appuyant sur les documents qu’il y trouve.
Cette approche transforme radicalement la nature de l’interaction avec l’IA. On ne demande plus à la machine de « savoir », on lui demande de « chercher et synthétiser ». Cette nuance est capitale : elle permet d’utiliser l’intelligence de raisonnement de l’IA sur des informations qui changent tous les jours, sans avoir à investir des sommes colossales dans des processus techniques complexes comme le fine-tuning. Le RAG garantit que l’IA reste ancrée dans la réalité de votre entreprise, agissant comme un collaborateur augmenté qui aurait lu l’intégralité de votre base documentaire en une fraction de seconde.
Le fonctionnement technique simplifié : de la donnée au sens
Pour comprendre comment le RAG opère ce miracle de précision, il faut s’immerger dans le concept de recherche sémantique. Traditionnellement, une recherche informatique repose sur des mots-clés : si vous cherchez « procédure incendie », l’ordinateur cherche exactement ces caractères. Le RAG, lui, utilise des « embeddings ». Ce processus transforme chaque paragraphe de vos documents en une suite de coordonnées mathématiques (un vecteur) représentant son sens profond. Ainsi, le système comprend que « consignes de sécurité » et « évacuation des locaux » sont des concepts proches de votre requête, même si les mots diffèrent.
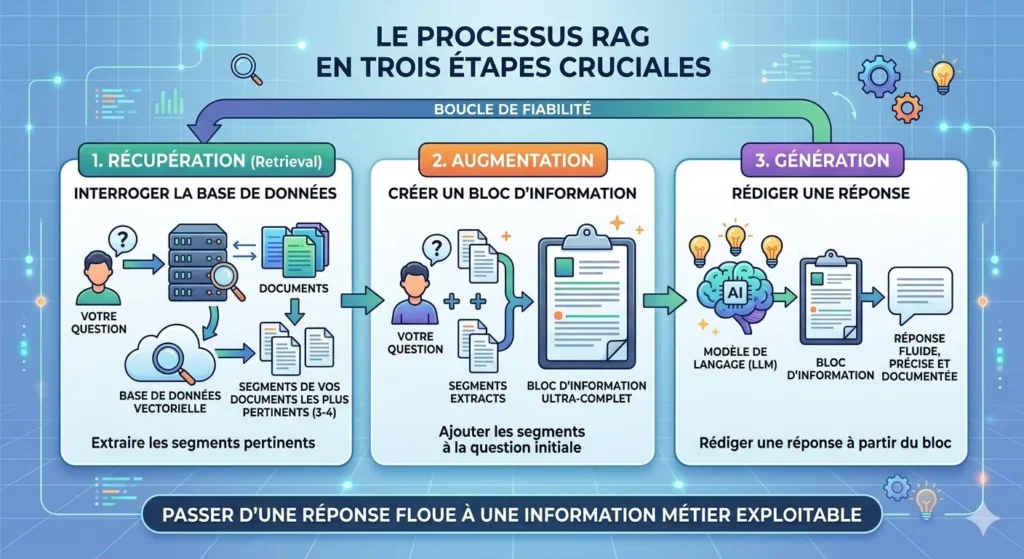
Le processus se déroule en trois étapes invisibles pour l’utilisateur mais cruciales pour la fiabilité. Tout d’abord, la phase de Récupération (Retrieval) : lorsque vous posez une question, le système interroge une base de données vectorielle pour extraire les trois ou quatre segments de vos documents les plus pertinents. Ensuite, la phase d’Augmentation : ces segments sont ajoutés à votre question initiale pour créer un bloc d’information ultra-complet.
Enfin, la phase de Génération : le modèle de langage reçoit ce bloc et rédige une réponse fluide, précise et documentée. C’est cette boucle qui permet de passer d’une réponse floue à une information métier exploitable.
Pourquoi le RAG est-il indispensable pour l’entreprise ?
L’adoption du RAG répond à trois problématiques majeures : la vérité, la sécurité et le coût. Le premier fléau de l’IA est l’hallucination, cette tendance des modèles à inventer des faits avec aplomb. En entreprise, l’erreur n’est pas une option. Le RAG agit comme une laisse de sécurité : en forçant l’IA à citer ses sources et à ne travailler que sur un contexte fourni, on réduit le taux d’erreur à un niveau quasi nul. La traçabilité devient possible : pour chaque réponse, l’utilisateur peut vérifier quel document original a été utilisé, renforçant ainsi la confiance des collaborateurs dans l’outil.
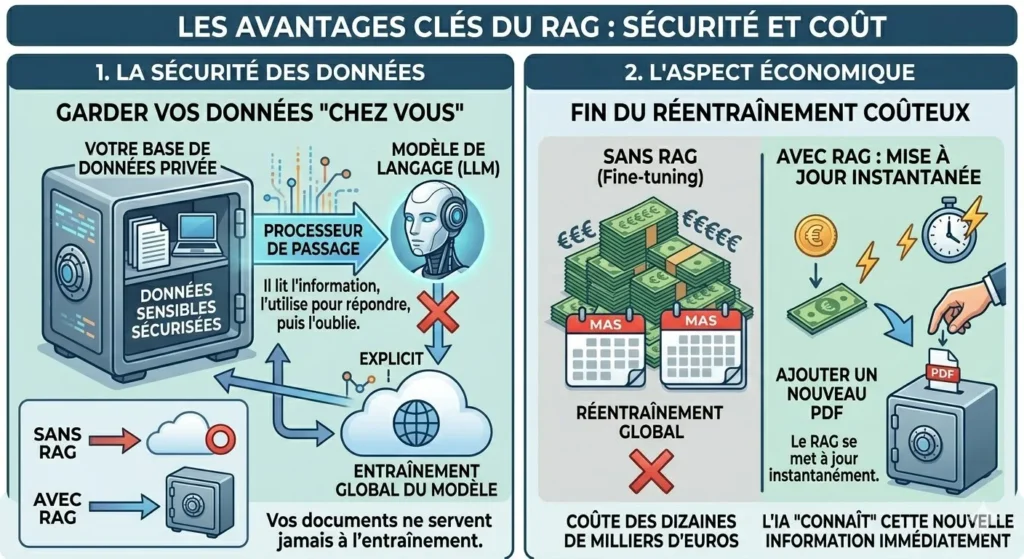
Ensuite, la sécurité des données est au cœur des préoccupations. Utiliser une IA publique avec des données sensibles est souvent un frein juridique majeur. Le RAG permet de garder vos données « chez vous ». Le modèle de langage n’est qu’un processeur de passage ; il lit l’information, l’utilise pour répondre, puis l’oublie. Vos documents ne servent jamais à l’entraînement global du modèle.
Enfin, l’aspect économique est décisif. Là où le réentraînement d’un modèle (fine-tuning) coûte des dizaines de milliers d’euros et devient obsolète dès qu’un document change, le RAG se met à jour instantanément : il vous suffit d’ajouter un nouveau PDF dans votre base pour que l’IA « connaisse » cette nouvelle information.
Les usages concrets en entreprise
Les domaines d’application du RAG touchent tous les pans de l’organisation. Au sein du service client, il permet de créer des chatbots de nouvelle génération qui ne se contentent pas de réponses scriptées, mais qui consultent les manuels techniques et l’historique des tickets pour résoudre des pannes complexes en un temps record. Dans les départements juridiques, le RAG devient un assistant capable de scanner des milliers de baux commerciaux ou de contrats de vente pour identifier des clauses spécifiques ou des risques de non-conformité par rapport à une nouvelle loi, avec une précision chirurgicale.
Pour les ressources humaines, le RAG transforme la gestion des connaissances internes. Un collaborateur peut interroger l’assistant sur la politique de télétravail, les avantages sociaux ou les procédures de formation, et obtenir une réponse personnalisée basée sur la convention collective et le règlement intérieur de l’entreprise. Enfin, dans les bureaux d’études ou les services de R&D, il permet de capitaliser sur des décennies d’archives techniques souvent inaccessibles car trop volumineuses. Le RAG redonne vie au patrimoine informationnel de l’entreprise en le rendant « discutable » par n’importe quel employé autorisé.
L’Efficacité Opérationnelle
Le RAG ne remplace pas l’expertise humaine : il la démultiplie. En supprimant la recherche manuelle dans des milliers de pages, il redonne à vos collaborateurs le temps de se concentrer sur l’analyse et la décision.
La Maîtrise du Risque
Contrairement à une IA standard, le RAG est « bridé » par vos données. S’il ne trouve pas la réponse dans vos documents, il l’indique au lieu d’inventer, garantissant une vérité métier absolue.
Les défis de mise en œuvre : La qualité de la donnée
Le déploiement d’un RAG n’est pas une baguette magique ; c’est un projet de gestion de la donnée. Le dicton « Garbage in, Garbage out » prend ici tout son sens. Si vos documents sources sont obsolètes, contradictoires ou mal structurés, l’IA, malgré toute son intelligence, restituera des informations erronées. La première étape d’un projet RAG réussi est donc le nettoyage et la hiérarchisation de l’information. Il faut s’assurer que le système accède à la version « faisant foi » d’un document et non à un brouillon datant d’il y a trois ans.
Un autre défi de taille est la gouvernance des droits d’accès. Une IA augmentée ne doit pas devenir une faille de sécurité permettant à n’importe qui de consulter des documents confidentiels. Il est impératif d’intégrer une couche de gestion des permissions : le système de récupération doit être « conscient » de qui pose la question et ne présenter à l’IA que les documents que cet utilisateur a le droit de voir. Enfin, il y a le défi du « chunking », c’est-à-dire le découpage intelligent des documents. Découper un texte au milieu d’une phrase peut faire perdre tout son sens au contexte. Une expertise technique est donc nécessaire pour paramétrer le système de manière à ce que les fragments d’information transmis à l’IA soient toujours cohérents et complets.
Donnez une mémoire d’entreprise à votre IA.
Ne laissez pas vos données dormir dans des dossiers inaccessibles. Transformez votre base documentaire en un assistant intelligent, sécurisé et expert de votre métier.
Vers une mémoire d’entreprise augmentée
Le RAG représente la maturité de l’intelligence artificielle appliquée au monde professionnel. Nous ne sommes plus dans l’expérimentation de gadgets capables de rédiger des poèmes, mais dans la mise en place d’une véritable infrastructure de connaissance. En connectant la capacité de raisonnement des grands modèles de langage à la fiabilité et à la confidentialité de vos données privées, vous créez une mémoire collective augmentée, infatigable et accessible.
L’investissement dans une solution RAG est le moyen le plus sûr de pérenniser votre transformation numérique. C’est la garantie de passer d’une IA qui « sait parler » à une IA qui « connaît votre métier ». En maîtrisant cette architecture, vous ne vous contentez pas de suivre la tendance de l’IA, vous construisez un actif stratégique qui valorise chaque document, chaque compte-rendu et chaque procédure produit par votre organisation.